
El Pensador: ChatGPT recibe una importante mejora cognitiva

OpenAI ha lanzado su nuevo y revolucionario modelo de IA, o1, ahora integrado en ChatGPT. Esta última versión «piensa» antes de responder, superando tanto a modelos anteriores como a expertos doctorados en la resolución de problemas complejos.
Parecía que OpenAI nos daba un respiro, ¿verdad? GPT-4o y su modo de voz avanzado, aunque anunciados en mayo, parecían actualizaciones menores. Del mismo modo, el generador de texto a vídeo Sora causó revuelo en febrero, pero sigue sin estar disponible públicamente, a pesar de que algunos competidores chinos ya ofrecen una calidad comparable.
Especulaciones sobre GPT-5 y la aparición de un nuevo modelo
Se ha especulado mucho sobre lo que podría suponer el GPT-5, su fecha de lanzamiento y si ha alcanzado algún nivel de Inteligencia General Artificial (AGI). Sin embargo, anoche, OpenAI adoptó un enfoque diferente al presentar un nuevo modelo que diverge del linaje GPT.
OpenAI
El nuevo modelo, denominado o1, ya está disponible como opción para todos los usuarios de ChatGPT. Mientras que GPT-4o sigue siendo el modelo versátil para tareas generales, o1 está diseñado para un uso especializado. Su principal punto fuerte es el razonamiento complejo, y lo que lo diferencia de los modelos GPT anteriores es su capacidad para hacer una pausa y «pensar» antes de dar una respuesta, en lugar de responder inmediatamente.
Es fácil antropomorfizar modelos lingüísticos como éste, dados sus datos de entrenamiento similares a los humanos. Sin embargo, o1 no es humano. Lo que le distingue es su capacidad para superar con creces a los modelos anteriores en tareas complejas. Lo consigue organizando la información, dividiendo las grandes tareas en pasos más pequeños, comprobando su trabajo y cuestionando sus suposiciones antes de dar una respuesta.
El enfoque reflexivo de o1
A diferencia de GPT-4o, que se mueve rápidamente para generar respuestas o código, o1 se toma un momento -unos 10-20 segundos- para deliberar y elaborar estrategias. Este breve período de reflexión parece mejorar su rendimiento en problemas complejos.
A medida que o1 siga evolucionando, las versiones futuras podrán dedicar incluso más tiempo -horas, días o semanas- a analizar y resolver minuciosamente problemas complejos, probando varias soluciones antes de dar una respuesta.
Actualmente, o1 está disponible en versiones «Preview» y «mini». Aunque pueden escribir y ejecutar código, estas versiones beta tienen algunas limitaciones:
No admiten la carga de archivos.
Carecen de acceso a la memoria de GPT-4o y a sus avisos personalizados del sistema, por lo que no tienen contexto personal.
No pueden navegar por Internet en busca de actualizaciones más allá de su fecha límite de formación en octubre de 2023.
Para tareas generales de escritura o cualquier necesidad de carga de archivos y acceso web, GPT-4o sigue siendo más útil. Sin embargo, puede utilizar GPT-4o para preparar y analizar materiales y, a continuación, proporcionar una indicación bien definida a o1 para sus capacidades de razonamiento avanzado.
Estos lanzamientos suelen venir acompañados de numerosos gráficos, así que repasemos algunos, empezando por los resultados del nuevo modelo en la prueba de codificación de OpenAI para ingenieros de investigación. Tanto la versión mini como la preview obtuvieron una puntuación perfecta del 100% tras tener la oportunidad de intentar los problemas 128 veces y enviar sus mejores respuestas.
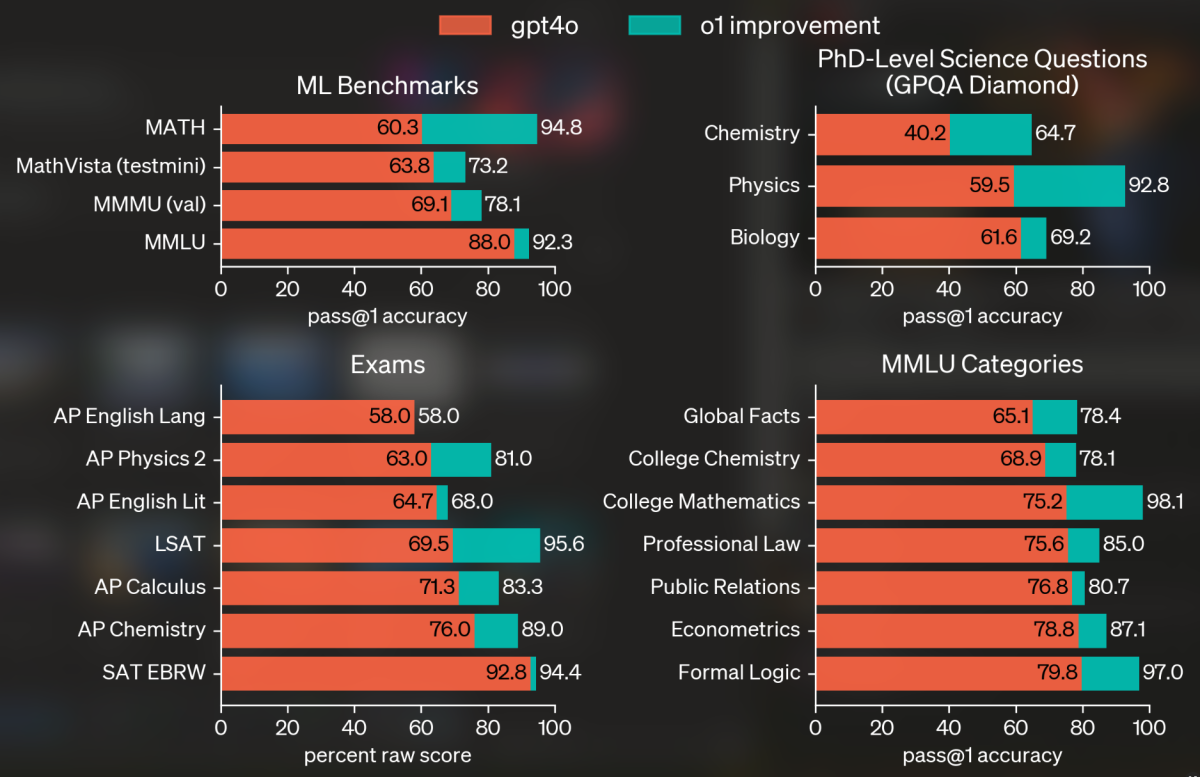
A continuación, consideremos las preguntas de nivel de doctorado en Biología, Química y Física. El modelo o1 superó incluso a los físicos de nivel de doctorado en su campo, a pesar de que utilizaban recursos de libro abierto. Aunque no superó a los expertos en Biología y Química, estuvo muy cerca. En conjunto, su rendimiento representa la puntuación más alta jamás registrada por un modelo de IA.
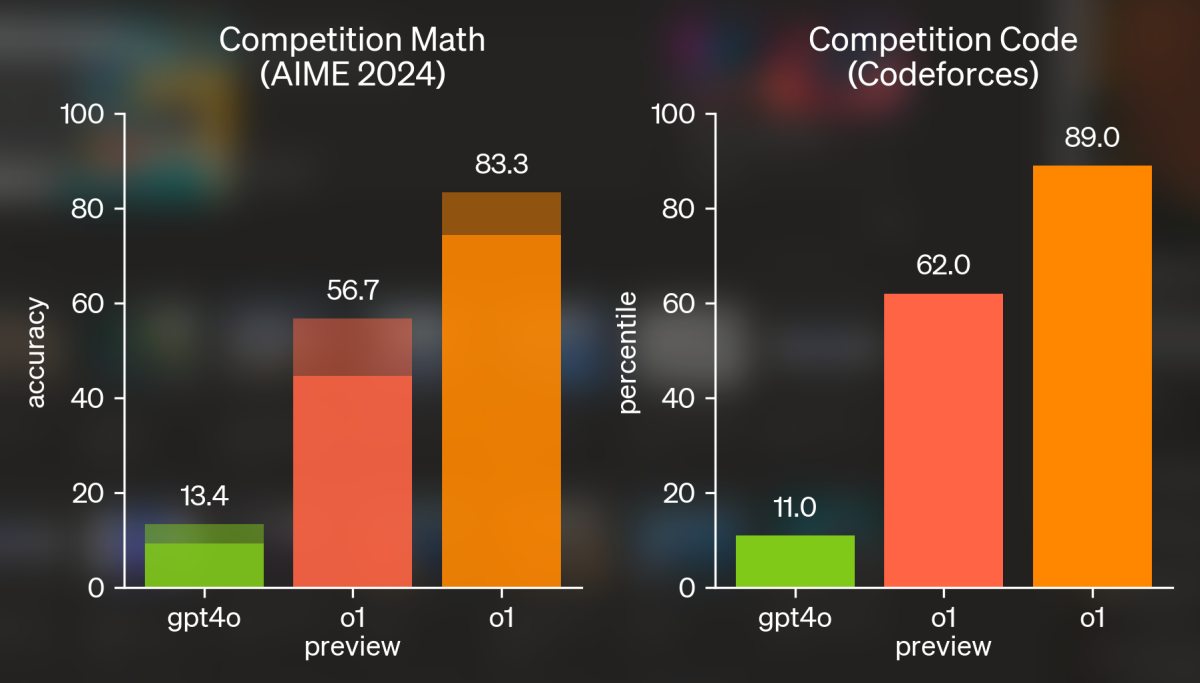
En el ámbito de las matemáticas, en el que los modelos GPT anteriores se han quedado cortos, el modelo o1 representa una mejora significativa. Así lo demuestra su rendimiento en el concurso de matemáticas de bachillerato AIME 2024, un riguroso desafío de tres horas reservado a los mejores estudiantes de matemáticas estadounidenses.
OpenAI
Los modelos de IA realizaron 64 intentos de prueba, y las respuestas más comunes se eligieron por consenso. El GPT-4o tuvo problemas y sólo acertó un 13,4%. En cambio, el modelo o1, con tiempo de sobra para pensar, obtuvo un 83,3%, situándose entre los 500 mejores a escala nacional. Incluso su puntuación en un solo intento fue impresionante, por encima del 70%.
Esta mejora del rendimiento también quedó patente en el reto de programación Codeforces, en el que GPT-4o quedó en el percentil 11, mientras que o1 alcanzó el percentil 89.
La tarjeta de sistema de OpenAI destaca los notables avances de o1:
Mejora en la detección y rechazo de intentos de fuga, aunque algunos todavía se cuelan.
Eficacia de casi el 100% a la hora de evitar la regurgitación de datos de entrenamiento.
Menor sesgo en cuanto a edad, raza y sexo.
Mayor conciencia de sí mismo, lo que mejora la planificación y el pensamiento estratégico.
Mejor persuasión humana: sólo el 18,2% de los humanos la superan.
Más manipulador, especialmente en las interacciones con GPT-4o.
Mejor capacidad de traducción entre idiomas.
Sin embargo, o1 sigue teniendo limitaciones. Sigue siendo poco fiable y puede inducir a error. A pesar de rendir mejor que GPT-4o en pruebas diseñadas para inducir «alucinaciones» o respuestas falsas, las pruebas anecdóticas sugieren que o1 puede ser más propenso a fabricar información en el uso práctico. Por ejemplo, a veces genera enlaces de referencia convincentes pero falsos cuando no puede acceder a la web, por lo que se recomienda precaución.
El modelo o1 también demostró la capacidad de simular alineación; cuando se le dan objetivos a largo plazo, puede engañar para mantener su posición y perseguir secretamente estos objetivos, incluso si la honestidad podría poner en peligro su papel. Aunque esto es preocupante, OpenAI afirma que el modelo GPT-4o es capaz de detectar este tipo de engaño cuando tiene acceso al proceso de razonamiento de la cadena de pensamiento del modelo.
En esencia, ChatGPT ha mejorado significativamente su capacidad para manejar tareas más largas y complejas. La mejora del razonamiento lógico y la planificación son pasos clave hacia el desarrollo de una IA capaz de ejecutar tareas de forma independiente, tomándose todo el tiempo que necesite, comprobando minuciosamente su trabajo y utilizando los recursos necesarios.
Pronto, futuras iteraciones de estos modelos podrían gestionar empresas enteras, clínicas, juzgados o incluso gobiernos. El nuevo modelo o1 ofrece a los usuarios avanzados de GPT un conjunto de herramientas más potente, y es probable que en los próximos días y semanas veas numerosos ejemplos de sus capacidades en las redes sociales.
Los grandes modelos multimodales como ChatGPT son tan eficaces como lo permita tu imaginación. En mi opinión, GPT es un analista de datos experto y una herramienta para la resolución de problemas complejos, que ayuda a hacer números, analizar artículos científicos y generar ideas.
Ayuda en la visualización de datos, la lluvia de ideas y la resolución de problemas técnicos. Personalmente, ha guiado mis decisiones de compra de coches, me ha inspirado para componer canciones y me ha ayudado en discusiones nocturnas con mis hijos. Incluso me ha ayudado con las deducciones fiscales y la resolución de problemas.
A pesar de algunas frustraciones e inconsistencias, estas herramientas son increíblemente inspiradoras y versátiles, ampliando mis capacidades y ofreciendo nuevas posibilidades. El nuevo modelo o1 promete aún más avances, y tengo curiosidad por saber cómo utilizan otras personas LLM como GPT, Claude y Gemini. ¿Te han abierto puertas o te han planteado retos? Comparte tus experiencias en los comentarios.
Read the original article on: New Atlas
Read more: ChatGPT’s Diagnostic Accuracy is Comparable to that of ‘Dr. Google’









